<SQL从入门到实战>笔记 作者: bluish 时间: 2025-02-09 分类: 笔记 #基础语句 ## 基础 语法顺序 select-from-where-group by-having-order by-limit 执行顺序 from/join-where-group by-having-select-order by-limit 列别名:Select、Order by 表别名:From、Join 查看结构:describe field ## select from https://sqlzoo.net/wiki/SELECT_from_WORLD_Tutorial select 字段 from 表 ``` select name, continent, area, popuolation, gdp from world #可前后调整顺序 select * from world #查询所有字段 select name as 名称 from wolrd #修改展示名称,也可省略as select distinct contient from world #contient列值去重;select distinct放一起;如果多字段则共同去重(同时重复) select name, gdp, population, gdp/population average_gdp from world #人均gdp计算,select时直接计算,加减乘除、函数 ``` ##where 查询语句,查询出来内容后筛选,条件判断 ```sql select from (where) ``` ``` select name, gdp, population, gdp/population average_gdp from world #可直接计算 where population >= 200000000 select name,population from world where name = 'germany'#英文单引号 ``` 查询既包含有所有元音字母(a,e,i,o,u),同时国家名中没有空格的国家,最后显示他们的名字 ``` select name from world where name like '%a%' and name like '%e%' and name like '%i%' and name like '%o%' and name like '%u%' and name not like '% %'; ``` <> 非 between and 之间(包含两边),需要左小右大 and 且 or 或 not 取反 is null 空值 in 条件范围 ###where/like ``` select name,population from world where name in('sweden','norway','denmark') #in条件范围,注意逗号分隔 WHERE name = 'sweden' OR name = 'norway' OR name = 'denmark'; #明确写出每次字段名 select name from world where name like 'C____ia' #like '通配符文本',%任意次数,_一次。 select name from world where name like '_t%'#筛选第二位字母为t的国家 ``` LIKE的右侧需为静态字符串,可以用concat('%',name,'%')构建动态字符串。 ####where多字段匹配 (column1, column2, ...) IN (subquery) 题:现在运营想要找到每个学校gpa最低的同学来做调研,请你取出每个学校的最低gpa。 ``` select device_id, university, gpa from user_profile where (university,gpa) in ( select university, min(gpa) gpa from user_profile group by university ) order by university ``` ##order by order by 字段 asc/desc #升序/降序ascent/descent ``` select winner,yr,subject from nobel where winner like 'Sir%' order by yr desc, winner asc #年份降序,名字升序;依次作为排序依据;默认为升序(可以不写asc) select winner,subject from nobel where yr=1984 order by subject in ('chemistry','physics'), subject, winner #in返回0、1,得到1按默认升序排最后。 select name from world order by area desc limit 3 #取前几个数值,limit限制查询 limit 3,4 #从3+1行开始的4行。4、5、6、7 limit x,n #x+1行开始返回n行 ``` ##聚合函数 数据的汇总信息,如汇总、均值、最大最小、行数 sum, avg, max, min, count 会忽略空值行 如avg(gdp<sup>195个值(含3个null)</sup>)=sum(gdp<sup>192</sup>)/count(gdp<sup>192</sup>) ``` select sum(population) from world where continent='africa' select count(*), count(name) from world ``` 在不使用group by时使用聚合函数,select只能写聚合函数或包含聚合函数的算式。 > select max(gpa) gpa from user_profile where university='复旦大学' https://www.nowcoder.com/share/jump/7965046151739625511869 使用group by后,select只能写聚合函数或group by分组了的字段。 group by为聚合依据,否则为整体。 **如果select中有窗口函数,如`SELECT SUM(a)OVER(β)`,只需满足α被group by,β无需满足。** count组合:count(distinct id, date) ###group by ``` select continent, count(name) from world group by continent #分大洲统计国家数量 #查询2013至2015年每年每个科目的获奖人数,结果按年份从大到小,人数从大到小排序 select yr, subject, count(winner) from nobel where yr between 2013 and 2015 group by yr, subject #依照字段顺序分组,前后调换含义不一样。 order by yr desc, count(winner) desc #查询每个大洲和该大洲里人口数超过1千万的国家的数量 select continent,count(name) from world where population > 10000000 group by continent ``` **规则上,where放在group by之前,以节约计算资源。** ###group by和distinct的区别 gour by是分组,虽然单独使用返回的都是唯一字段值,但后续聚合函数会对各组进行计算。 distinct依照字段去重,字段组的组合值具有独特性。如果想去除完全相同的行数据,必须使用 DISTINCT 对所有字段进行去重。可用`distinct *`。独特数据。 ##having 聚合后对组筛选,放在group by后。 having只能写聚合函数或group by分组的字段。 查询**总人口数至少为3亿**<sup>2-having</sup>的**大洲和其平均gdp**<sup>1-group by/select</sup>,其中**只有gdp高于200亿且人口数大于6000万或者gdp低于80亿且首都中含有三个a的国家的计入计算**<sup>3-where</sup>,最后**按国家数从大到小排序**<sup>4-order by</sup>,只**显示第一行**<sup>5-limit</sup> ``` select continent, avg(gdp) from world #4 where gdp>20000000000 and population >60000000 or gdp<8000000000 and capital like '%a%a%a%' #3 group by continent #1 having sum(population)>=300000000 #2 order by count(name) desc limit 1 查询人均gdp大于3000的大洲及其人口数,仅gdp在200亿和300亿之间的国家计入计算 select continent, sum(population) from world where gdp between 20000000000 and 30000000000 group by continent having sum(gdp)/sum(population)>3000 ``` ###having和where 的区别 **where对参与结果的行设置条件。having对参与结果的分组设置条件。**having筛选的是组整体,而不是组中的每个记录。 ##常见函数 ###数学函数 - round(x,y) #x值四舍五入y位, round(3.15,1)返回3.2, round(13.15,-1)返回10 ###字符串函数 - concat('a','b') #字符串连接函数,返回"ab",**concatenate连结** - replace(s,s1,s2) #将s中的s1替换成s2 - left(s,a) right(s,b) #截取左侧/右侧n个字符。 - substring(s,n,len) #第n个起len个,没有len则截到最后。n可以为负数。 - substring_index(string, '切割标志', 位置数(负号:从后数,截取后部)) #从前数,截取前部。 如substring_index(blog_url,'/',-1):在blog_url字段中,从右数第一个'/'处,截取后部内容。 - char_length(content) 字符串长度 ###数据类型转换函数 - cast(x as type) #将x值转换成另一个类型 ###时间日期函数 - year/month/day(date)分别返回date日期格式中的年/月/日。 - weekday(date)返回周几 - date(time)从中提取日期部分(年月日),如2021-09-25 - date_add(date,interval num unit) 时间加 date_sub(date,interval num unit) 时间减,**subtract减去** example: date_add('2023-10-01',interval 5 day) - datediff(date1,date2) 计算两日期间隔天数,时间不参与计算,可以返回负数。迟的时间在前面,前减后。 - TIMESTAMPDIFF(unit, datetime_expr1, datetime_expr2) 如果单独时间相减会有问题。迟的时间在后面,后减前。 > 直接减时间,其实是相当于把:去掉之后的数字相减,比如01:25-0:25结果是100 - date_format(date,'format') 日期和时间替换格式,直接返回替换后的值。 **如果field的类型是datetime,则可直接比较时间(2020-04-20 00:00:00),而无需转换格式** 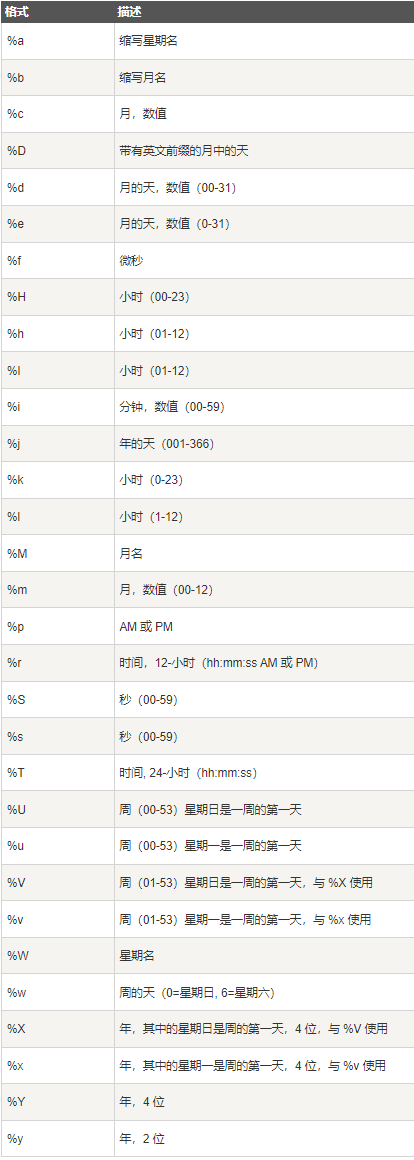 ###条件判断函数 - if(s,r1,r2) s为true返回r1,false返回r2 - case when两种用法 - case s when c1 then 'r1' when c2 then 'r2' else 'r3' end #简单case,if的多重扩展,**一值与多候选值判断**。 - case when 1>0 then 'r1' else 'r2' #类似if,替代多重if。搜索式case,**多条件/字段搜索,从上至下仅匹配一个**。 ``` CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 ... ELSE result_default END ``` Expample:round和concat嵌套得到百分比数据 ``` select confirmed ,deaths ,recovered ,recovered/confirmed ,concat(round((recovered/confirmed)*100,2),'%') 治愈率 from covid where recovered/confirmed > 0.3 ``` ###limit x,n与substring(s,x,n)的区别 limit中理解为“跳过”或“分页”,跳过前x个,取n个值。 substring(s,x,n)则是从x个起取n个,包括x。 ##Union 合并两个查询的结果,`UNION`会去重,`UNION ALL`不去重。 ``` select device_id, gender, age, gpa from user_profile where university='山东大学' UNION ALL select device_id, gender, age, gpa from user_profile where gender='male' ``` #高级语句 ##窗口函数 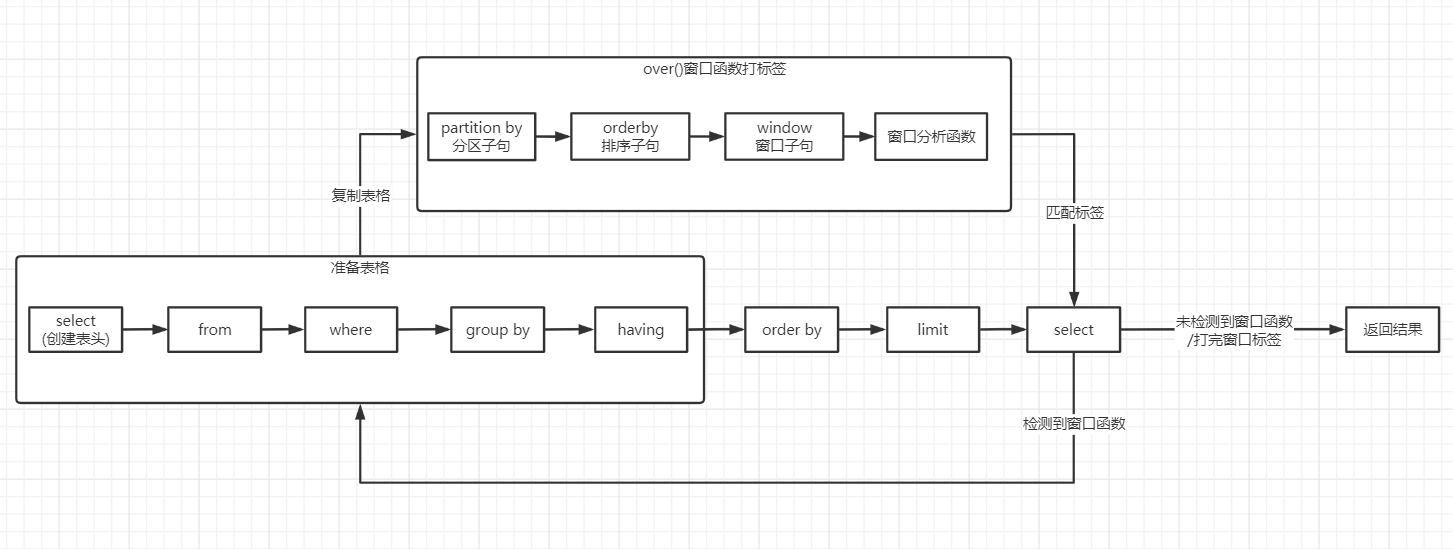 ###over() ``` window_function (expression) OVER ( [ PARTITION BY part_list ] [ ORDER BY order_list ] [ { ROWS | RANGE } BETWEEN frame_start AND frame_end ] ) ``` - PARTITION BY 表示将数据先按 part_list 进行分区 - ORDER BY 表示将各个分区内的数据按 order_list 进行排序 - ROWS | RANGE 表示 Frame 的定义,即:当前窗口包含哪些数据? - ROWS 选择前后几行,例如 ROWS BETWEEN 3 PRECEDING AND 3 FOLLOWING 表示往前 3 行到往后 3 行,一共 7 行数据(或小于 7 行,如果碰到了边界) - RANGE 选择数据范围,例如 RANGE BETWEEN 3 PRECEDING AND 3 FOLLOWING 表示所有值在 $[c-3,c+3]$ 这个范围内的行,$c$ 为当前行的值 ###排序 - rank() 1,1,3,4 并列占位 - dense_rank() 1,1,2,3 并列不占位 - row_number() 1,2,3,4 不并列顺序 ###偏移分析 - lag(s,1) 滞后一项,向上取,查询逻辑由上至下。 - lead(s,1) 超前一项,向下取。 ###聚合窗口函数 许多聚合函数也可以作为窗口函数使用,如avg()、sum()、count()、max()、min()等。 查询意大利每周新增确诊数(显示每周一的数值 weekday(whn) = 0) 最后显示国家名,标准日期(2020-01-27),每周新增人数,按照截至时间排序。 ``` select name,date_format(whn,'%Y-%m-%d'), confirmed-lag(confirmed,1)over(order by whn) from covid where name='Italy' and weekday(whn)=0 order by whn desc ``` ####Order by在聚合窗口函数的不同作用 在聚合窗口函数中使用over(order by)时,order by的作用为:**排序+截取第一行到当前行的范围。** 所以sum(field)over(order by *specfic field*)为自上而下的每行累加值:`RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW` 参考:[SQL 窗口函数的优化和执行](https://zhuanlan.zhihu.com/p/80051518 "SQL 窗口函数的优化和执行") ##表连接 select field from sheet1`inner join/left join/right join` sheet2 on sheet1.field=sheet2.field **key字段匹配** | 连接类型 | 基准表 | 返回记录范围 | NULL 情况 | |--------------|--------|--------------------------|------------------------------------| | `INNER JOIN` | 无 | 只返回匹配的记录 | 不匹配的记录会被排除,不会产生 NULL | | `LEFT JOIN` | 左表 | 左表所有记录 + 右表匹配记录 | 右表无匹配时,右表字段为 NULL | | `RIGHT JOIN` | 右表 | 右表所有记录 + 左表匹配记录 | 左表无匹配时,左表字段为 NULL | | `OUTER JOIN` | 无 | 返回匹配记录 + 各自不匹配的记录| 任意一方无匹配时,另一方字段为 NULL | 可视化:https://joins.spathon.com/ 多个匹配:各自成行,数量相乘;新增行数为相乘数量减基准数量。 表连接建议使用别名。 多表连接时,若字段名唯一,可以不指定表明;如果字段名不唯一,则需指定表名,**即使是链接键**,如sheet1.field/sheet2.field。 查询至少出演过第1主角30次的演员名 ``` select name from casting c join actor a on c.actorid = a.id where ord = 1 #先用order筛选,count无法直接条件,除非搭配case group by name having count(movieid)>=30 ``` https://sqlzoo.net/wiki/The_JOIN_operation 查询每场比赛,每个球队的得分情况,按照以下格式显示: 最后按照举办时间(mdate)、赛事编号(matchid)、队伍1(team1)和队伍2(team2)排序 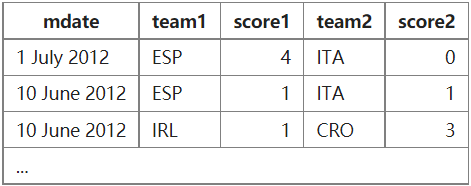 ``` select mdate, matchid, team1, count(case when teamid=team1 then 1 end) score1, team2, count(case when teamid=team2 then 1 end) score2 #count或sum都可以,记得then 1 end from game join goal on game.id=goal.matchid #连接game和goal表 group by mdate, matchid, team1, team2 #独特场次 order by mdate, matchid, team1, team2 ``` ###SELF JOIN (is inner join)  ##子查询 嵌套查询。子查询结果作为主查询的一部分。运行优先于主查询,从内而外。 **什么时候会用到子查询:需要获得某些计算值(聚合、窗口、函数)或筛选值,并进一步对值进行挑选(比较、匹配、筛选)或加工(聚合、窗口)。** **使用from的情况:子查询新独特字段的挑选、外加工** ###派生表 子表一定要命名。 ####题1(内获值<sup>聚合</sup>,外挑选) 查询出gdp高于欧洲每个国家的所有国家名,有一些国家gdp值可能为NULL,请排除这些国家,外挑选):查询出gdp高于欧洲每个国家的所有国家名,有一些国家gdp值可能为NULL,请排除这些国家 ``` select name from world where gdp is not null and gdp>( select max(gdp) from world where continent='europe' ) ``` ####题2(内获值<sup>窗口</sup>,外挑选<sup>from-新生成独特字段</sup>) 查询2017年所有在爱丁堡的选区当选议员所在选区(constituency)及其团队(party),已知爱丁堡选区编号为S14000021至S14000026,当选议员即各选区得票数最高的候选人 思路1(**from子查询**;rank替代最值,窗口函数不改变原表,最高/最低-desc/asc) ``` select constituency, party from ( select constituency ,party ,votes ,rank()over(partition by constituency order by votes desc) as posn from ge where constituency between 'S14000021' and 'S14000026' and yr = 2017 ) as rk where rk.posn = 1 ``` 思路2(illegal,弃用) ``` select yr,constituency, party from ge where (constituency,votes) in( select constituency,max(votes) from ge #聚合值的匹配 where constituency between 'S14000021' and 'S14000026' and yr=2017 group by constituency) order by constituency ``` 子查询多列匹配:(column1, column2, ...) IN (subquery) ####题3(内获值<sup>筛选</sup>,外挑选) 查询所有国家人口均≤25000000的大洲,及其国家名(name)和人口(population) 思路1:聚合函数筛选人口最大值小于25000000大洲,匹配大洲获数据。 ``` select continent,name,population from world where continent in( select continent from world group by continent having max(population)<=25000000 #利用聚合值筛选continent ) ``` 思路2:所有人口大于25000000国家匹配大洲,未匹配到的大洲满足条件。匹配大洲获数据。 ``` select name ,continent ,population from world where continent not in ( select distinct continent from world where population >25000000 ) ``` ####题4(内获值<sup>窗口</sup>,外加工<sup>窗口</sup>) 查询德国和意大利每天新增治愈人数并从高到低排名,查询结果按国家名,截至日期(输出格式为'xxxx年xx月xx日'),新增治愈人数,按排名排序 由于窗口函数不能嵌套,所以分两层。 ``` select name, whn, daily, rank()over(partition by name order by daily desc) rank from ( select name, whn, recovered-lag(recovered,1)over(partition by name order by whn) daily from covid where name ='italy' or name='france' ) as subcovid order by rank ``` ####题5(内获值<sup>聚合</sup>,外加工<sup>聚合</sup>) 统计每个学校的答过题的用户的平均答题数 https://www.nowcoder.com/share/jump/7965046151739639350180 **平均值的二次加工可以直接在子查询中:count()/count(distinct())** ``` select university, avg(num) avg_answer_cnt from( select university, count(question_id) num from question_practice_detail q left join user_profile u on q.device_id=u.device_id #改成join应该一致 group by university, q.device_id ) as subtable group by university order by university ``` ####题6(内获值<sup>筛选</sup>,外加工<sup>聚合</sup>) 现在运营举办了一场比赛,收到了一些参赛申请,表数据记录形式如下所示,现在运营想要统计每个性别的用户分别有多少参赛者,请取出相应结果。 ``` select gender, count(*) number from ( select case when profile like '%,male' then 'male' when profile like '%female%' then 'female' end as gender from user_submit ) as sub group by gender ``` ####题7(内获值<sup>函数</sup>,外加工<sup>聚合</sup>) 题目:现在运营举办了一场比赛,收到了一些参赛申请,表数据记录形式如下所示,现在运营想要统计每个年龄的用户分别有多少参赛者,请取出相应结果 ``` select age, count(*) number from( select device_id, substring_index(substring_index(profile,',',-2),',',1) age from user_submit ) as sub group by age ``` #### 外加工Group By,内加工无Group By的情形下,可直接用单层查询。如题6、题7: ``` #题6 select case when profile like '%,male' then 'male' when profile like '%female%' then 'female' end as gender, count(*) number from user_submit group by case when profile like '%,male' then 'male' when profile like '%female%' then 'female' end #题7 select substring_index(substring_index(profile,',',-2),',',1) age, count(*) number from user_submit group by substring_index(substring_index(profile,',',-2),',',1) ``` ###标量子查询 需要获取一个单一值(标量子查询),可以出现在SQL语句中任何可以使用单个值的位置。 ``` DATEDIFF((SELECT MAX(DATE(end_time)) FROM tb_user_video_log), MAX(DATE(end_time))) ``` 一定情况下可以被聚合窗口函数替代,但聚合窗口函数只能用在select中。 聚合运算放在标量子查询中,不要套在标量子查询外。 ##WITH ``` WITH 别名A AS (替代子查询A), 别名B AS (替代子查询B), ... 别名N AS (替代子查询N) SELECT * From A B ... N ``` 可以替代子查询,可读性更强,但效率更低。 #常见问题 - 别名仅用于查询展示,不能被重复调用计算。 - SQL别名后就不能用真名。 - select group by时,多个字段的组合是去重、独特的。 注意select出来的结构,一些字段可能indistinct - 多个sql语句,每个结束后用封号';',如果union则不用 - 只有is null和is not null,不能'= null' - 在select中:既有聚合函数又有非聚合字段时,注意group by非聚合字段 - 在select中:窗口函数不能外部套窗口函数,也不能外部套聚合函数,可以套普通函数。 - **在去重上,优先使用distinct,而非group by** 如果要去重用distinct,要计算分组值用group by - 如果结果是1、0(比如相减)则直接用,不必case筛选。 - rank为保留字,不能用rank别名。 - 连接表时,无运算需求可以直接from join,而不需放在子查询中。 - case的每个条件前面都要加when。 - 避免字段类型混淆:如case1='100',case2=100 - max/min是聚合函数 - 子查询在SQL的主要子句中也可以使用,如select、where、having - 有错误优先检查逗号 - 聚合函数内部不能嵌套子查询。 - 排序函数是没有参数的,如rank()、dense_rank()、row_number() - date_sub/add别忘了interval n day(other unit) - 外层查询中,表别名需要重新定义。如sub中有o1(别名表).uid,则主查询中需使用sub.uid - 外部where、group by等筛选,不会影响到SELECT中的标量子查询(another select) #总结/经典 ##不同函数使用方法的区别 ###使用位置 |使用位置 |聚合函数 |窗口函数 |窗口聚合函数 | |------------|--------|--------|------------| |SELECT 子句 |✅ 允许 |✅ 允许 |✅ 允许 | |WHERE 子句 |❌ 不能 |❌ 不能 |❌ 不能 | |GROUP BY 子句|✅ 允许 |❌ 不能 |❌ 不能 | |HAVING 子句 |✅ 允许 |❌ 不能 |❌ 不能 | |ORDER BY 子句|✅ 允许 |✅ 允许 |✅ 允许 | 窗口函数在Having之后才窗。 聚合函数需要Where时仍未分组。 ###使用方法 窗口聚合函数不能进行Distinct ##获取最大值的多种方法 处于**分组中**为例: 1. 使用`GROUP BY + ORDER BY + LIMIT` group by *specfic field*; order by desc; limit 1 2. 使用`RANK()窗口函数` rank(field)over(partition by *specfic field* order by field desc) 3. 使用`MAX + GROUP BY` max(field); group by *specfic field* 4. 使用`MAX窗口函数` max(field)over(*specfic fiel*) ##同一时刻数量 将进入设为1,退出设为2,UNINO双表 用聚合窗口函数`sum()over(order by time)`算递增,按时间排序。 https://www.nowcoder.com/share/jump/7965046151740890587841 ``` select artical_id, max(uv) max_uv from( select artical_id, time, sum(in_out)over(partition by artical_id order by time asc, in_out desc) uv from( select artical_id, in_time time, 1 in_out from tb_user_log UNION all select artical_id, out_time time, -1 in_out from tb_user_log ) sub where artical_id <> 0 )sub2 group by artical_id order by max_uv desc ``` ##连续签到/周期重置 通过`日期减排名`的方式(需要去重对应,如`distinct 未去重date, dense_rank()`)的方式获取temp_date,temp_date相同的date为连续签到。 通过取余`%`来界定非整月周期。 https://www.nowcoder.com/share/jump/7965046151741181535821 ``` select uid, date_format(sign_date,'%Y%m') month, sum(score) coin from( select uid, sign_date, temp_date, case row_number()over(partition by uid,temp_date order by sign_date)%7 when 3 then 3 when 0 then 7 else 1 end as score from( select distinct uid, date(in_time) sign_date, date(in_time)-dense_rank()over(partition by uid order by date(in_time)) temp_date from tb_user_log where artical_id=0 and sign_in=1 and date(in_time) between '2021-07-07' and '2021-10-31' )sub )sub2 group by uid,date_format(sign_date,'%Y%m') order by DATE_FORMAT(sign_date,'%Y%m'),uid ``` ##展现指定字段值/动态时间范围 指定字段值: 1. WHERE筛选+GROUP BY 2. 单独写+最后UNION 动态时间范围: 1. BETWEEN DATE_SUB(date_now, INTERVAL 6 DAY) AND date_dynamic 2. datediff 3. 非distinct的窗口聚合函数: count(sth)over(order by date rows between n1 preceding and n2 following ) <pre> WITH date_range AS ( SELECT DISTINCT date(event_time) as dt FROM tb_order_overall WHERE date(event_time) BETWEEN '2021-10-01' AND '2021-10-03' ), merge AS ( SELECT DISTINCT o3.product_id, date(event_time) dt FROM tb_order_overall o1 JOIN tb_order_detail o2 ON o1.order_id = o2.order_id JOIN tb_product_info o3 ON o2.product_id = o3.product_id WHERE date(event_time) BETWEEN '2021-09-25' AND '2021-10-03' AND shop_id = 901 ) SELECT d.dt, ROUND(COUNT(DISTINCT m.product_id) / (SELECT COUNT(DISTINCT product_id) FROM tb_product_info WHERE shop_id = 901), 3) sale_rate, ROUND(1 - COUNT(DISTINCT m.product_id) / (SELECT COUNT(DISTINCT product_id) FROM tb_product_info WHERE shop_id = 901), 3) unsale_rate FROM date_range d LEFT JOIN merge m ON m.dt BETWEEN DATE_SUB(d.dt, INTERVAL 6 DAY) AND d.dt GROUP BY d.dt ORDER BY d.dt; </pre> ##特定标签 https://www.nowcoder.com/share/jump/7965046151742311139632 |age_cnt|num| |-|-| |25岁以下|4| |25岁及以上|3| 1. UNION <pre> select '25岁以下' age_cut, count(*) number from user_profile where age<25 or age is null UNION select '25岁及以上' age_cut, count(*) number from user_profile where age>=25</pre> 2. 子查询筛选并标记,主查询分组Count <pre> select age_cut, count(age_cut) number from( select if(age>=25,'25岁及以上','25岁以下') age_cut from user_profile ) sub group by age_cut</pre> ##不同条件的对应计算 1. 通过子查询分开计算 子查询算result=1,主查询算无限制条件。 <pre>select main.user_id, pass_distincted/count(distinct question_id) question_pass_rate, pass_indistincted/count(*) pass_rate, count(*)/count(distinct question_id) question_per_cnt from( select user_id, count(distinct question_id) pass_distincted, count(question_id) pass_indistincted from done_questions_record where result_info=1 group by user_id ) sub join done_questions_record main on main.user_id=sub.user_id group by main.user_id,pass_distincted,pass_indistincted having question_pass_rate>0.6</pre> 2. 计算时引入if/case when <pre> select user_id, count(distinct <mark>if(result_info=1,question_id,null)</mark>)/count(distinct question_id) question_pass_rate, sum(result_info)/count(*) pass_rate, #或者count(<mark>if (result_info=1,question_id,null)</mark>)/count(*) count(*)/count(distinct question_id) question_per_cnt from done_questions_record group by user_id having count(distinct if(result_info=1,question_id,null))/count(distinct question_id)>0.6</pre> <SQL从入门到实战>笔记 https://bluish.net/archives/2150/ 作者 bluish 发布时间 2025-02-09 许可协议 CC BY-SA 4.0 复制版权信息 标签: none